1. 前言数组和链表是数据结构的基石,是逻辑上可描述、物理结构真实存在的具体数据结构。其它的数据结构往往在此基础上赋予不同的数据操作语义,如栈先进后出,队列先进先出…… 数组中的所有数据存储在一片连续的内存区域;链表的数据以结点形式存储,结点分散在内存的不同位置,结点之间通过保存彼此的地址从而知道对方的存在。 因数组物理结构的连续特性,其查询速度较快。但因数组的空间大小是固定的,在添加、插入数据时,可能需要对空间进行扩容操作,删除时,需要对数据进行移位操作,其性能较差。 链表中的结点通过地址彼此联系,查询有点繁琐,查询过程有点像古时候通过烽火传递军情一样。而插入、删除操作则较快,只需要改变结点之间的地址信息就可以。 可认为链表是由结点组成的集合实体,根据结点中存储信息的不同,可把链表分成: - 单链表:结点中存储数据和其后驱结点的地址。
- 循环链表:在单链表的基础上,其最后一个结点,也称尾结点中存储头结点的地址,形成一个闭环。
- 双向链表:结点中存储数据和前、后驱结点的地址。
- 双向循环链表:在双向链表的基础上,头结点保存尾结点地址,尾结点保存头结点地址。一般说双向链表都是指双向循环链表。
在链表的基本形式之上,可以根据需要在结点上添加更多信息,如十字链表等复杂形式。在链表基础认知之上,请不要拘泥于知识本身,而要善于根据实际需要进行变通。 本文聊聊基于单链表形式的数据查询、插入、删除操作。 2. 单链表单链表的特点是结点中仅存储数据本身以及后驱结点的地址,所以单链表的结点只有 2 个域: - 存放数据信息,称为数据域。
- 存放后驱结点的地址信息,称为指针域。
如下图描述了单链表结点的存储结构: 
C++中可以使用结构体描述结点:
typedef int dataType;
struct LinkNode{
dataType data;
LinkNode *next;
LinkNode(dataType data) {
this->data=data;
this->next=NULL;
}
};
当结点与结点之间手牵手后,就构成了链表: 
链表有 2 个特殊结点:
- 头结点:链表的第一个结点,头结点没有前驱结点。头结点可以存储数据,也可以不存储数据,不存储时,此结点为标识用的空白结点,可在链表操作时提供便利。关于第一结点的问题在后文会详细介绍。
- 尾结点:链表中的最后一个结点,在单链表中其后驱结点的地址为
NULL,也就是没有后驱结点。
链表需要一个LinkNode类型的变量(head)用来存储头结点地址,对于整个链表的操作往往都是从head保存的头结点开始。 链表还应该提供维护整个结点链路的基本操作算法(抽象数据结构):
class LinkList {
private:
LinkNode *head;
int length;
public:
LinkList() {}
LinkNode * getHead() {
return this->head;
}
void initLinkList() {}
LinkNode * findNodeByIndex(int index) {}
void createFromHead(int n) {}
void createFromTail(int n) {}
LinkNode * findNodeByVal(dataType val) {}
int instertAfter(dataType val,dataType data) {}
int insertBefore(dataType val,dataType data) {}
int delNode(dataType data) {}
void delAll() {}
void showSelf() {}
~LinkList() {
this->delAll();
}
};
2.1 初始化链表由多个结点组成,因头结点没有前驱结点,所以需要一个变量存储其地址,此变量称为链表的head首地址。后续操作基本都是顺着首地址"顺滕摸瓜"。 当head为NULL时,说明此链表为空链表。一般会在初始化时,为head变量存储一个没有实际数据语义的标志性结点,也称为空白头结点。 所以初始化时,会有 2 种方案: 
void initLinkList() {
this->head=NULL;
}
- 设置
head指向一个没有实际数据语义的空白结点,此结点仅起到标志作用。

void initLinkList() {
this->head=new LinkNode(0);
}
是否一定要提供一个标志性的空白头结点,这不是必须的,但是有了这个空白头结点后,会为链表的操作带来诸多的便利性。一般在描述链表时,都会提供空白头结点。
2.2 创建单链表创建单链表有 2 种方案: - 创建过程中,新结点替换原来的头结点,成为新的头结点,也称为头部插入创建方案。如构建数据为
{4,9,12,7}的单链表。
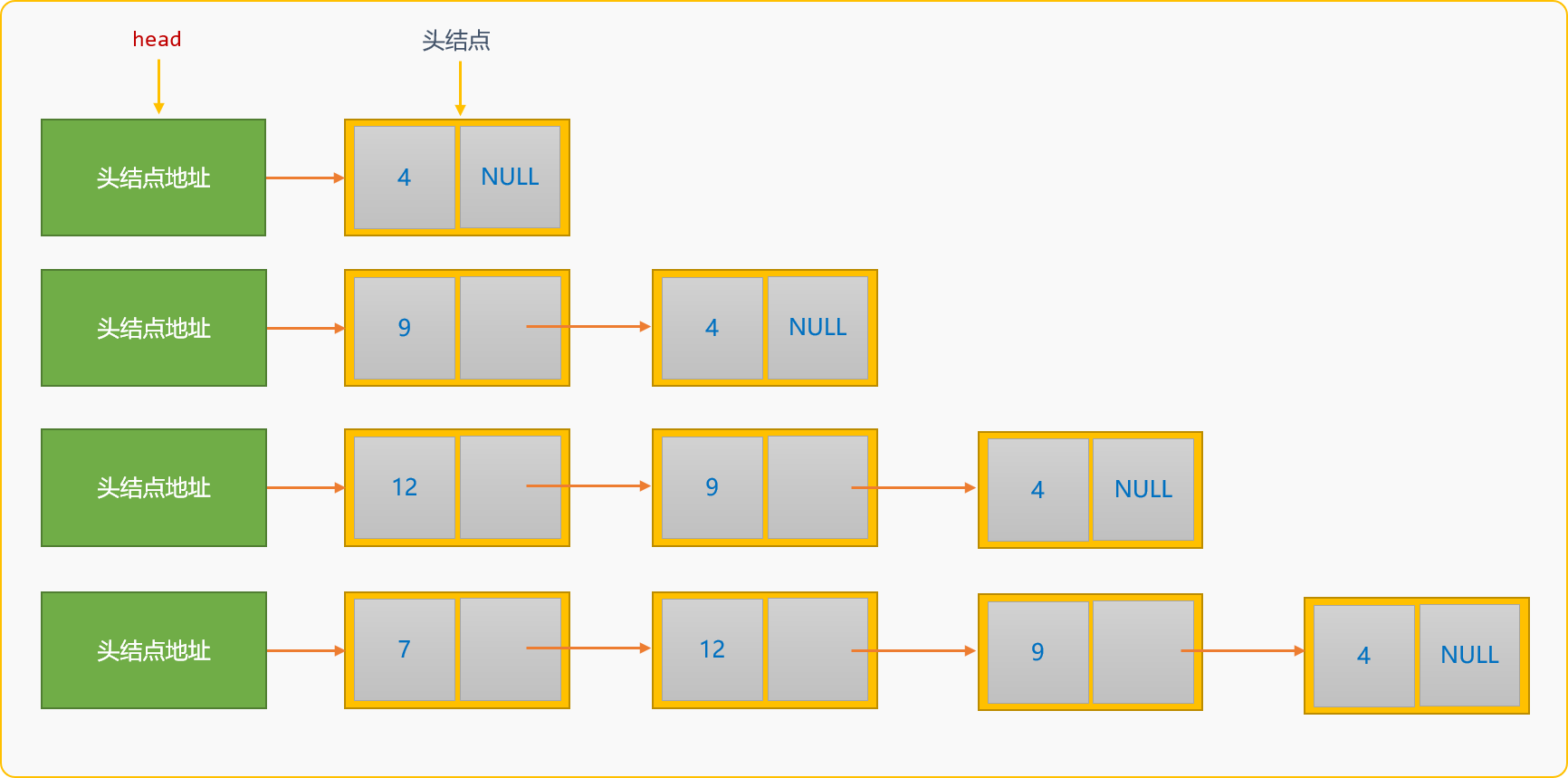
头部插入创建单链表后,数据在链表中的存储顺序和数据的逻辑顺序是相反的。如上图所示。 注:上述插入演示没有带空白结点。
代码实现:
void createFromHead(int n) {
LinkNode *newNode,*p;
p=this->head;
for(int i=0; i<n; i++) {
newNode=new LinkNode();
cin>>newNode->data;
newNode->next=p;
p=newNode;
}
}
添加 3 个结点,测试上述创建的正确性。 LinkList list;
list.createFromHead(3);
LinkNode * head= list.getHead();
cout<<"输出结点信息"<<endl;
cout<<head->data<<endl;
cout<<head->next->data<<endl;
cout<<head->next->next->data<<endl;
执行结果: 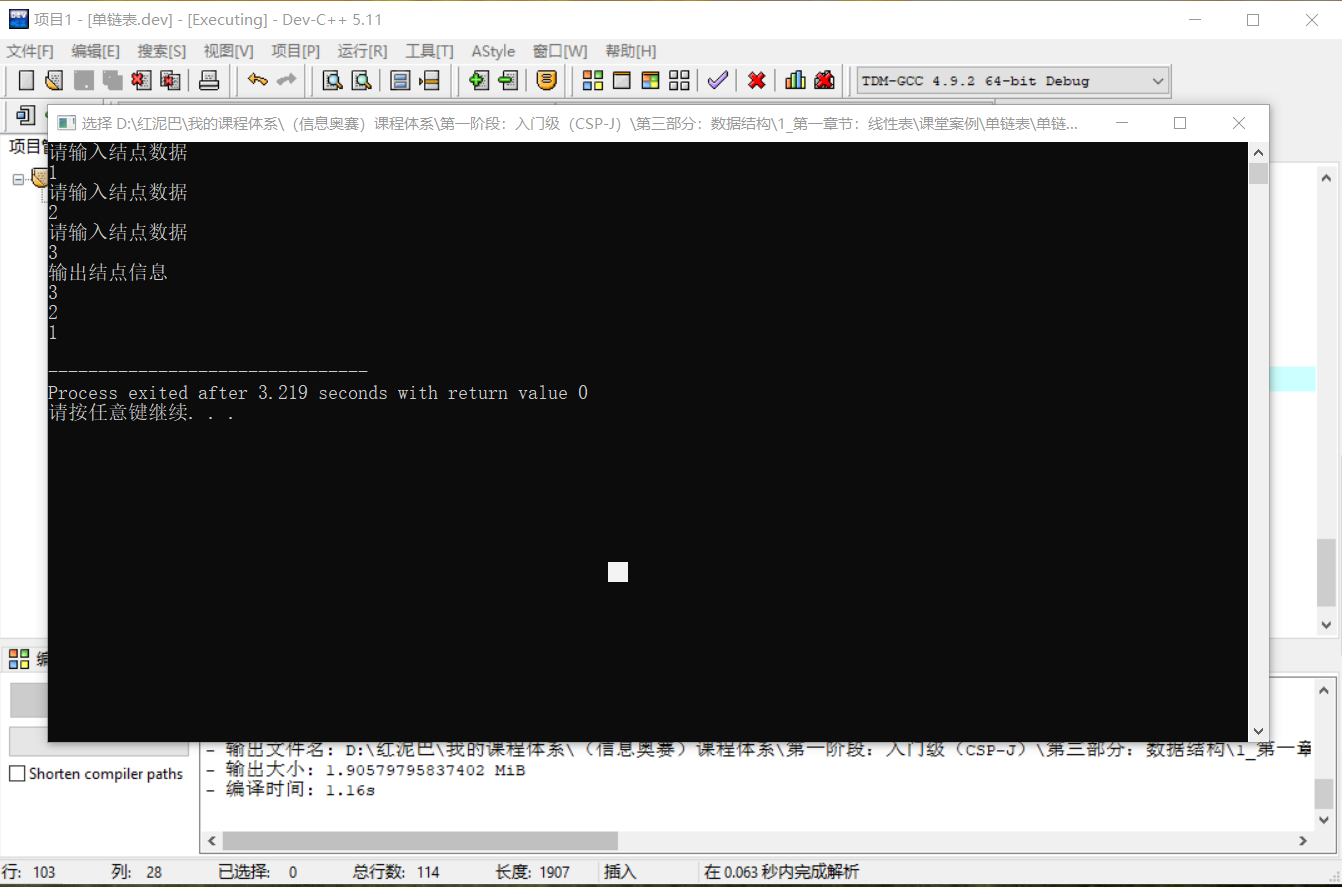
从结果可知,输入顺序和输出顺序是相反的。 - 尾部插入创建单链表,创建时的新结点替换原来的尾结点。如构建数据为
{4,9,12,7}的单链表。
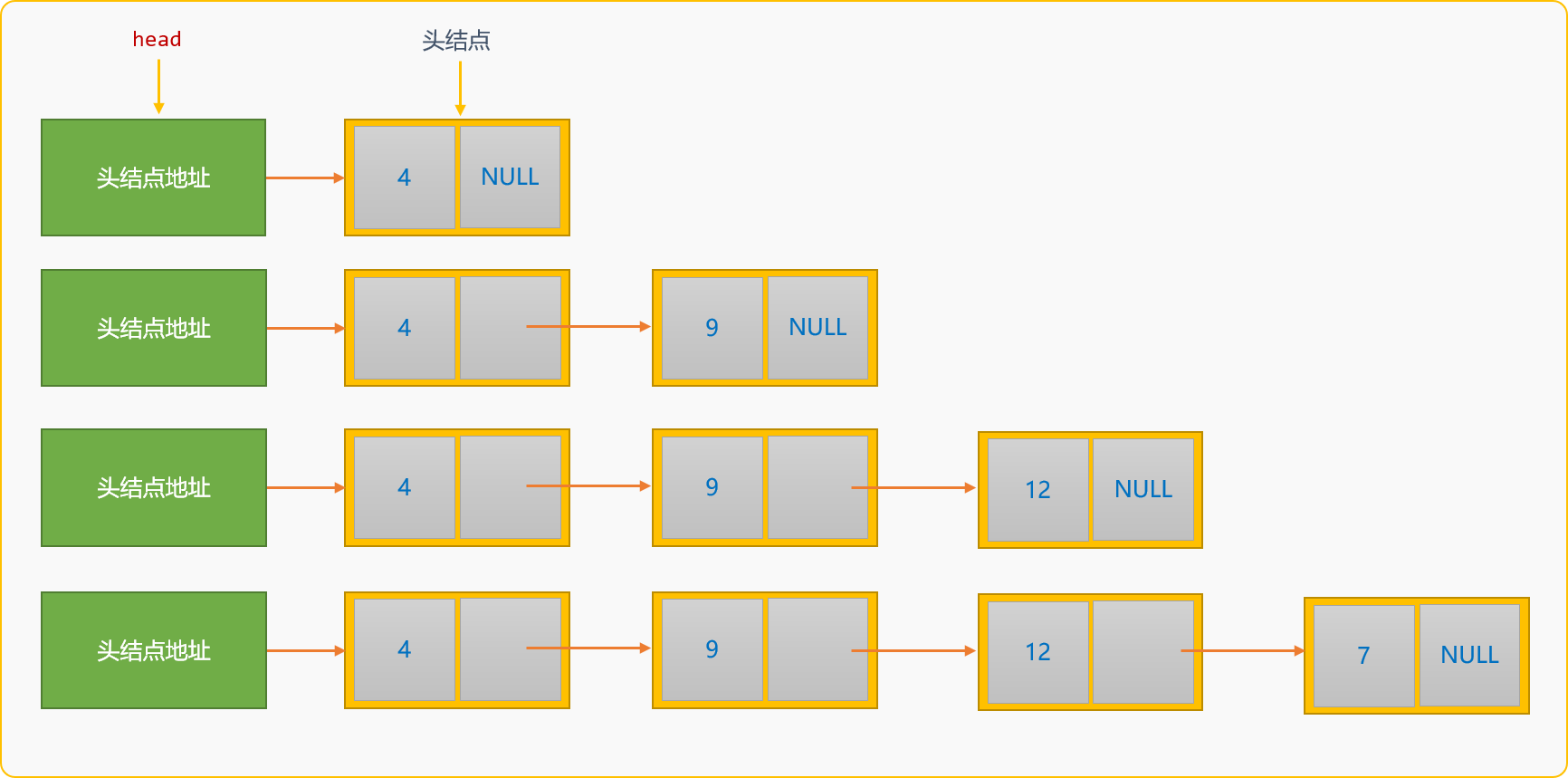
尾部插入方案创建的单链表,数据在链表中的存储顺序和数据的逻辑顺序是一致,从而也能保证最终读出来顺序和输入顺序是一致的。 与头部插入创建算法不同,除了需要存储头结点的地址信息,尾部插入算法中还需要一个tail变量存储尾结点的地址。初始时,tail和head指向同一个位置。 代码实现:
void createFromTail(int n) {
LinkNode *newNode,*p,*tail;
p=this->head;
tail=this->head;
for(int i=0; i<n; i++) {
newNode=new LinkNode(0);
cout<<"请输入结点数据"<<endl;
cin>>newNode->data;
if(p==NULL) {
p=tail=newNode;
} else {
tail->next=newNode;
tail=newNode;
}
}
this->head=p;
}
测试尾部插入创建的正确性: int main(){
LinkList list {};
list.createFromTail(3);
LinkNode * head= list.getHead();
cout<<
关闭
站长推荐 /1 /1 
| 
